Kryzs,
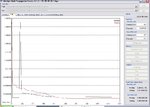
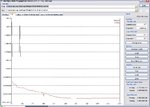
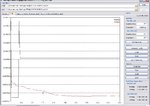
As you see on attached Multimarket training short report.pdf, the software change automatically the training from test pattern 281 (20% of training range) to calibration intervals 1125 (equal to training patterns). It is happened when I am using Turboprop as weight updating method (see NN #1, 3 and 4). It was not happened while using other method (momentum or vanilla), see NN #2.
I am sure it solve the training problem.
Arryex
As you see on attached Multimarket training short report.pdf, the software change automatically the training from test pattern 281 (20% of training range) to calibration intervals 1125 (equal to training patterns). It is happened when I am using Turboprop as weight updating method (see NN #1, 3 and 4). It was not happened while using other method (momentum or vanilla), see NN #2.
I am sure it solve the training problem.
Arryex