Krzysiaczek99
Well-known member
- Messages
- 430
- Likes
- 1
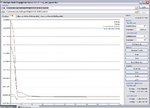
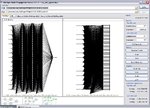
I'm not sure what's going on there Krzys, MBP will not give the same results every time you train a net, but in my experience they are not usually that different. Did you start with randomized weights? (See the FAQ at http://dit.ipg.pt/MBP/FAQ.aspx). Sometimes it gets stuck in a local minimum, but I have repeated the training several times and always get roughly the same result.RMS error ~ 0.005. Here is another image of another training run starting with randomized weights.
View attachment 77492
The bugs reported on the MBP site suggest that when you use CUDA you need to modify the registry because Windows does not like it when the GPU runs for more than 5 sec.. But maybe you already did this.(See Bug 2.1.1 beta - Blue Screen of Death with CUDA at http://dit.ipg.pt/MBP/bugs.aspx).
You are quite right, the data is not from Arry. I wanted more samples, so I collected data using the MT4 terminal on an MBT demo account. Here is the dated version of the data.
View attachment 77494
I made a mistake describing how I trained the net for the pictures. The net in the c file was trained with the test file active, because it must be to get the test RMS. But I tried several times without the test file and got roughly the same training RMS error. MBP does not optimize using the test data, so the only future leak is from the operator stopping training when the test rms error is minimized. I tried to ignore the test data for the images, so there should be small if any bias in the images. In the future, I will reserve a production set, and run the net on that set using the c code. That i s a bit of a pain, but I think as easy as using NS2 on a production set.
MBP is not perfect but I like it compared to alternatives.😀
fralo
Hi,
I think I found the problem. This discrepancy occurs only if i train using CUDA. For CPU training i've got similar results to yours. I informed Noel and he will release a new version of MBP soon.
I also tested 15-38-38-38-1 configuration with space network. See results seems to be worse RMS - 137 pips. For net without space net I've got 55 pips
Krzysztof