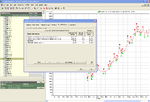
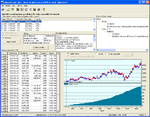
NSClassifier compare to PNN/GRNN in NS2:
- Do not require you to set parameters such as learning rate and momentum as NS2
- The nets can only have one output, while in PNN NS2 need to specify each outputs (0 or 1) then it said better with continuous value inputs rather than binary inputs.
- It grows hidden neurons as needed, and trains quickly while in NS2 the layer is fix and hidden neurons not automatically adjusted.
- There are two options either neural network or GA.
I will post and compare the result later.
Arry
- Do not require you to set parameters such as learning rate and momentum as NS2
- The nets can only have one output, while in PNN NS2 need to specify each outputs (0 or 1) then it said better with continuous value inputs rather than binary inputs.
- It grows hidden neurons as needed, and trains quickly while in NS2 the layer is fix and hidden neurons not automatically adjusted.
- There are two options either neural network or GA.
I will post and compare the result later.
Arry