AlgoSjoerd
Newbie
- Messages
- 3
- Likes
- 3
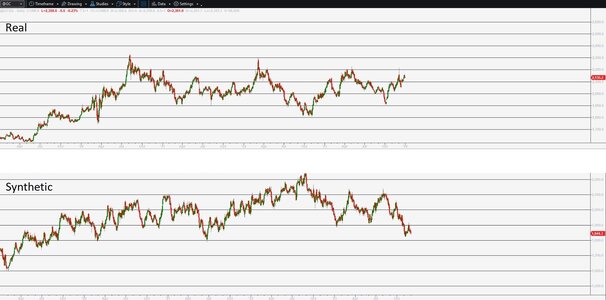
I recently completed a research project focused on creating synthetic data using Generative Adversarial Networks (GANs). This innovative approach has shown significant promise in enhancing trading strategy development by addressing overfitting challenges and expanding datasets.
Why Synthetic Data Works: Synthetic data mimics real-world data patterns and can be used in the same way as your regular OHLC data. By using GANs, we can generate high-quality, diverse datasets that improve the robustness and accuracy of trading models.
Why It’s Useful: You can generate an infinate amount of additional data, of each market and every specific timeframe. In addition, it enhances model performance by reducing overfitting, synthetic data helps create more reliable and profitable trading strategies.
I’ve seen impressive results, including a significant increase in trading profits and Sharpe ratio during my research.
I’m now looking to connect with others interested in exploring the benefits of synthetic data further, so please feel free to respond.
Why Synthetic Data Works: Synthetic data mimics real-world data patterns and can be used in the same way as your regular OHLC data. By using GANs, we can generate high-quality, diverse datasets that improve the robustness and accuracy of trading models.
Why It’s Useful: You can generate an infinate amount of additional data, of each market and every specific timeframe. In addition, it enhances model performance by reducing overfitting, synthetic data helps create more reliable and profitable trading strategies.
I’ve seen impressive results, including a significant increase in trading profits and Sharpe ratio during my research.
I’m now looking to connect with others interested in exploring the benefits of synthetic data further, so please feel free to respond.